




ng.28.66一款拥有大量高质量漫画作品的阅读平台,能给您带来非常舒适的阅读体验哦。战斗,可以见证各样经典战役,随时随地体验三国策略游戏乐趣,喜欢的朋友欢迎前来下载爽玩。

《ng.28.66》-专属于“三国迷”的RSLG手游,高度还原的战斗场面,古色古香的三国背景!千人争霸,万人国战!
爆发你心中的欲望,争霸、征服、把你不顺眼的一切以坟墓作为纪念碑,率领千军,成就超级群英!相信只有远征,才能让每一个关卡成为万人瞩目的经典三国战场,火烧赤壁,怒吼长坂坡,秋风五丈原,等着您来挑战!
经典战役
群英陪你玩转三国
战争策略
见证血与火的荣耀
即时战斗
还原真实三国战场
万人国战
一国之主谁与争锋
千名武将
耿耿忠心任你摆布

🐬⚡️欢迎使用🐬【ng.28.66】⚡️☁️️⚡️支持:32/64bit⚡️系统类型:ng.28.66(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《ng.28.66》是一款功能强大,非常专业的手机清洁软件。本软件功能齐全,支持存储加速,垃圾清除,文件清除,软件管理,图片优化,非常实用。
🍱百度百科🍱【ng.28.66】⚡️🚡⚡️支持:32/64bit⚡️系统类型:ng.28.66(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《ng.28.66》是一款为用户提供实时公交信息的手机应用程序。通过该应用,用户可以查询公交车线路、站点、车辆到站时间等信息,还可以实时跟踪公交车的位置和运行状态,方便用户出行。掌上公交的界面简洁清晰,操作简单方便。用户可以通过搜索线路和站点快速查询到所需信息,同时还可以设置附近站点提醒、历史记录、收藏等功能,方便用户个性化设置和管理。
🚑解答🚑【ng.28.66】⚡️☀️️⚡️支持:32/64bit⚡️系统类型:ng.28.66(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《ng.28.66》是一款去除了不必要功能的轻量级短视频应用。它的设计简洁明了,功能精简,使用流畅。用户可以浏览、创作和分享短视频,同时还可以下载和保存自己喜欢的视频。抖音极速版提供了各种热门话题和挑战活动,用户可以参与其中,与其他用户互动和交流。
🥄简介:🥄【ng.28.66】⚡️🗺️⚡️支持:32/64bit⚡️系统类型:ng.28.66(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《ng.28.66》是一款免费追剧神器,汇聚多家影视资源的视频平台,包括爱奇艺、腾讯视频、搜狐视频、优酷视频、芒果TV、哔哩哔哩、乐视、韩剧TV、人人视频、pptv等全部高清电影、电视剧、动漫、综艺、资讯、短视频等,涵盖全网影视资源,美剧、韩剧、日剧、泰剧、TVB等海量资源库,高清大片、热播好剧、爆笑综艺、人气动漫等;你想看的想追的想关注的,全部内容免费观看。
🕓🔥欢迎使用🕓【ng.28.66】⚡️♌️️️⚡️支持:32/64bit⚡️系统类型:ng.28.66(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《ng.28.66》是一款Suunto手机端软件,suunto手表app与Suunto
🍄【欢迎使用】🍄【ng.28.66】⚡️🎋️⚡️支持:32/64bit⚡️系统类型:ng.28.66(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《ng.28.66》是一款高额度、低息费、无担保的信用贷款产品。凭身份证即可申请,简单三步操作,即可享受宜享花专属额度。快速贷款,实时审批,快速到帐,循环额度,一次申请,循环使用,持牌借贷平台,科技护航,实力雄厚。
💺科普盘点💺【ng.28.66】⚡️🍶⚡️支持:32/64bit⚡️系统类型:ng.28.66(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《ng.28.66》是一款金融理财应用,通过它,您可在线快速借到您需要的借款,查看个人的财富相关情况,满意的理财产品,一键就可快速添加,轻松获得稳健的高收益,让赚钱变得更简单,可查看信用卡的相关信息,在线立即还款等,非常的便利,功能丰富,操作简单,借款、投资、还信用卡……都可以,值得拥有。
🌴【首充即送!返利不限】🌴【ng.28.66】⚡️🥎⚡️支持:32/64bit⚡️系统类型:ng.28.66(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《ng.28.66》是一款非常容易使用的手机清洁和杀毒软件,只用于安卓机器。功能非常完整。它主要是免费的,没有广告,占用的内存很少,所以你的手机垃圾无处藏身。一键安装可以减少干扰。整理手机、清理垃圾、管理文件、储备文件都很实用。
🏦【欢迎使用】🏦【ng.28.66】⚡️🛴️⚡️支持:32/64bit⚡️系统类型:ng.28.66(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《ng.28.66》是一款资源广泛的小说阅读app,这个软件涵盖了广泛的小说资源!
第一步:选择/拖拽文件至软件中
点击“添加ng.28.66”按钮从电脑文件夹选择文件,或者直接拖拽文件到软件界面。
第二步:选择需要转换的文件格式 打开软件界面选择你需要的功能,ng.28.66支持,PDF互转Word,PDF互转Excel,PDF互转PPT,PDF转图片等。
第三步:点击【开始转换】按钮点击“开始转换”按钮, 开始文件格式转换。等待转换成功后,即可打开文件。三步操作,顺利完成文件格式的转换。。
完成任务与成就:积极完成游戏中的日常任务和成就,这些任务和成就通常会提供丰富的奖励,其中可能包括军机令。
参与活动:游戏中的精彩活动和竞技场战斗也是军机令的丰富来源。积极参与各类活动,完成相关任务,可能会获得额外的军机令奖励。
联盟协作:加入联盟并与其他成员协作,完成联盟任务和活动,有机会获得联盟成就奖励中的军机令。此外,联盟成员之间也可以相互分享军机令,增加大家的战略储备。
VIP特权与活动商城:成为VIP玩家通常能够享受到额外的特权,其中可能包括军机令的额外奖励。同时,游戏内的活动商城中可能也有军机令的购买选项。可以通过智慧运用VIP特权和活动商城,更高效地获取军机令。
副本与Boss挑战:挑战游戏中的副本和Boss,有机会获得额外的军机令奖励。提高自身战力,也是获取军机令的一种重要途径。
【苏州大量外企撤资?官方回应:不实******
据苏州市网络联合辟谣平台消息,近日,有网民在互联网传播“苏州大量外资企业撤离”。记者联系苏州市市场监督管理局了解到,该消息为不实信息。据苏州市市场监督管理局提供的相关数据显示:2024年10月,苏州市外资期末实有24639户,同比增长1.91%,较上月相比增加35户。与2023年12月相比增加近1000户(2023年12月底全市外资实有23640户)。
】【撤职、撤项后,黄飞若被撤稿****** 黄飞若 资料图
黄飞若 资料图
公开资料显示,黄飞若1999年进入华中农业大学读本科,2008年博士毕业后留校任教。他于2017年获评为教授、博士生导师,研究方向为动物分子营养学,曾担任华中农大动物科学技术学院动物营养与饲料科学系主任。
今年1月,华中农大11名硕士、博士研究生实名举报导师黄飞若存在篡改数据、编造实验结果等学术不端行为。
2月,华中农大发布通告称,黄飞若在学术、师德师风、财务等方面均存在一定问题,决定撤销其校内一切职务,解除聘用合同,并报请撤销其教师资格,报请对其相关科研论文、项目等撤稿、撤项。
今年10月,黄飞若因科研不端行为,被国家自然科学基金委员会监督委员会通报批评,并撤销其国家自然科学基金项目、追回已拨资金。
】【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】【【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!******
在这个智能驱动的时代,Wind在金融科技领域又迎来了两个令人振奋的好消息。万得投顾终端的“Wind AliceFC算法”不仅成功通过了国家互联网信息办公室的第九批深度合成服务算法备案,还荣获了上海金融科技产业联盟创新监管联合实验室主办的2024年度人工智能大模型金融领域示范场景及创新应用案例征集活动的优秀奖。这标志着AI技术在金融领域的深入应用,以及“Wind AliceFC”在这一领域的卓越表现和市场潜力。
科技赋能,AI⁺万得投顾终端AliceFC算法备案成功
国家互联网信息办公室正式发布了《第九批深度合成服务算法备案信息》的公告,由Wind自主研发的万得投顾终端“Wind AliceFC文本生成类算法” 顺利获得备案。这一成就不仅是“AI⁺万得投顾终端”发展的里程碑,也是对Wind在人工智能领域深耕细作成果的官方认可。

AI大模型金融领域创新大奖,AI⁺万得投顾终端AliceFC脱颖而出
与此同时,AI⁺万得投顾终端“Wind AliceFC”在由上海金融科技产业联盟创新监管联合实验室主办,2024年度人工智能大模型金融领域示范场景及创新应用案例征集宣传展示活动中,荣获创新应用案例类优秀奖。这一荣誉不仅是对团队不懈努力和创新精神的肯定,也预示着广阔的市场前景和机遇。

AliceFC,投资顾问的AI智能助手
科技在财富管理领域的应用正如火如荼,数字化转型和智能化升级已经成为财富管理机构必然的发展趋势。财富管理行业的根本能力是价值创造能力,财富管理的本质是为客户提供更专业更体贴的服务,实现客户财富的保值增值。谁能真正拥有科技加持的价值创造能力,以及顺应变化的新型服务模式,谁才能在新一轮的百舸争流中赢得先机。AliceFC聚焦业务场景,从投顾资讯到标的分析,从产品诊断到智能筛选,简化服务、攻克难题,为您焕新开启AI智能之旅。
环球财经资讯全掌握,有问必答,助你轻松应对客户咨询。
股票分析师无论是技术分析还是基本面分析,解答关于股票的任何问题。
基金诊断
全面、快速、智能地进行基金诊断,并给出适合理财场景的营销话术。
理财诊断覆盖全量银行理财产品数据,从基本信息、回报、持仓等维度进行全面诊断。
智能选基与产品擂台智能筛选基金产品,精准对比基金表现,最便利的基金推荐利器。
你是优秀的投资顾问,我是你的AI智能助手!
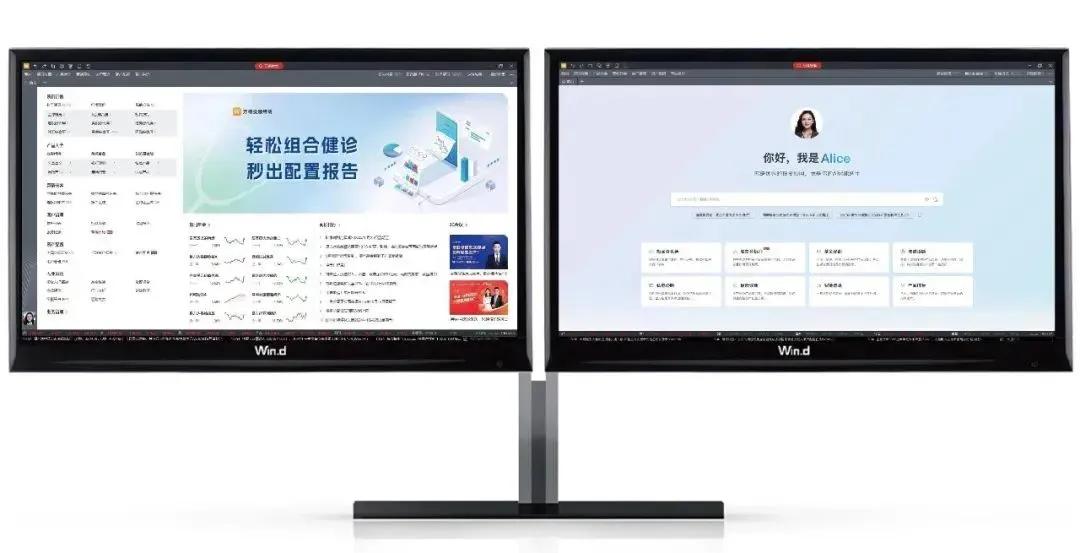
关于万得投顾终端
万得投顾终端是为投资顾问及理财师量身打造的一款结合业务全场景的一站式财富管理智能工作平台。基于过往的成熟服务经验,万得投顾终端深度连接财富管理条线8大业务场景需求:资讯行情、产品大全、获客营销、客户管理、资产配置、专业进阶、业务管理、AI智能助手。以数据、产品、研究、AI等能力,结合针对从业者成长进阶的培训体系赋能财富管理业务全条线,为金融机构提供财富管理数字化解决方案,赋能财富管理从业者更专业高效开展业务并不断学习成长进阶。
智能化的知识图谱分析,为您高效打破营销壁垒,打造大数据时代下的智能朋友圈,让您更了解您的客户。
产品擂台
全面、精准的对比两只基金,挖掘优秀基金的推荐话术。

引入了全新的功能模块,丰富了应用的功能性。
增加了社交分享功能,用户可以轻松地与朋友分享他们在应用中的活动。
新增了全新的用户界面,更加现代化和直观。
引入了全新的功能模块,丰富了应用的功能性。
添加了新的动画效果,提升了用户体验。
游戏版本优化
厂商名称:
官网:暂无
包名:net.joywii.qysg2d.uc
名称:ng.28.66
MD5值:10b1fe963d325f2df7d4a94b5e585a9d
金沙棋牌js6666手机版
下载pg麻将胡了试玩平台
下载云开·全站app登录网页入口
下载开元ky888棋牌官方版
下载南宫pg娱乐电子游戏官网
下载c7官网app下载安装
下载kaiyun云开网页版登录入口登录
下载pg电子麻将胡了
下载美高梅棋牌官网入口
下载星空体育app官方下载
下载ng.28.66
下载澳门新葡萄新京5303游戏特色
下载pg电子娱乐平台
下载南宫pg娱乐电子游戏官网
下载爱游戏app最新官网登录
下载ng28.666官网版
下载pg免费游戏试玩模拟器
下载九游体育
下载771771威尼斯.cmapp
下载365wm完美体育手机平台
下载问鼎app官方下载
下载j9游会真人游戏第一品牌
下载熊猫体育
下载im电竞
下载kaiyun云开网页版登录入口登录
下载pg麻将胡了试玩平台
下载星空综合体育app下载
下载j9游会真人游戏第一品牌
下载pg赏金女王单机版试玩平台
下载j9九游真人游戏第一平台
下载威尼斯wns.8885556
下载pg电子娱乐平台
下载南宫28ng娱乐平台游戏特色
下载免费pg电子游戏麻将
下载星空体育平台官网入口
下载j9游会真人游戏第一品牌
下载365wm完美体育手机平台
下载pg电子赏金试玩app
下载南宫28ng娱乐平台游戏特色
下载开元ky888棋牌官方版
下载pg免费游戏试玩模拟器
下载kaiyun全站网页版登录
下载j9九游真人游戏第一平台
下载南宫28ng娱乐平台游戏特色
下载美高梅棋牌官网入口
下载pg麻将胡了试玩平台
下载pg网赌软件下载
下载开元棋盘app官方版下载_开元棋盘app官网版下载-跑跑车
下载kaiyun全站app登录入口
下载澳门新莆京游戏app大厅
下载鼎盛平台下载入口
下载澳门新葡萄新京8883游戏特色
下载九游娱乐app官网,九游娱乐app官网下载苹果版
下载开元棋盘财神捕鱼官网版下载2023
下载大小单双赚钱平台
下载开元ky888棋牌官网版
下载星空体育app官方下载
下载星空·综合体育官网入口
下载星空·体育中国官方网
下载j9游会真人游戏第一品牌
下载kaiyun全站登录网页入口
下载pg赏金大对决试玩版
下载c7娱乐电子游戏官网
下载南宫28ng娱乐平台游戏特色
下载开元棋官方正版下载
下载南宫pg娱乐电子游戏官网
下载开元棋app官方下载
下载j9游会真人游戏第一品牌
下载kaiyun全站app登录入口
下载771771威尼斯.cmapp
下载pg娱乐电子游戏
下载云开·全站app登录网页入口
下载c7娱乐电子游戏官网
下载c7官网app下载安装
下载pg赏金大对决试玩版
下载壹号娱乐
下载ng.28.66
下载ng28.666官网版
下载pg赏金女王单机版试玩平台
下载j9九游真人游戏第一平台
下载澳门威尼克斯人网站
下载开元ky888棋牌官方版
下载爱游戏app官方入口最新版本
下载开yun体育官网入口登录体育
下载南宫pg娱乐电子游戏官网
下载九游体育
下载开yunapp体育官网入口下载手机版
下载澳门威尼克斯人网站
下载开元棋官方正版下载
下载免费pg电子游戏麻将
下载澳门威尼克斯人网站
下载kaiyun全站登录网页入口
下载鼎盛平台下载入口
下载j9游会真人游戏第一品牌
下载ng.28.66
下载j9九游真人游戏第一平台
下载爱游戏app官方入口最新版本
下载开yunapp体育官网入口下载手机版
下载pg电子娱乐平台
下载kaiyun官方网站登录入口
下载![双色球25年003期[如意]本期号码综合预测](http://yunan.www.www.chongqing.bjssckj.cn/uploads/images/66866.jpg) 双色球25年003期[如意]本期号码综合预测
双色球25年003期[如意]本期号码综合预测 《保卫要塞》玩法介绍第三期,出征攻占玩法
《保卫要塞》玩法介绍第三期,出征攻占玩法 利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力 《问道》新服挑战一触即发 海量元宝等你来拿
《问道》新服挑战一触即发 海量元宝等你来拿 2023155期天齐大哥和值迷
2023155期天齐大哥和值迷 伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启 《保卫要塞》玩法介绍第三期,出征攻占玩法
《保卫要塞》玩法介绍第三期,出征攻占玩法 《问道》双线新服今日开启 精彩福利送不停
《问道》双线新服今日开启 精彩福利送不停 《闪耀暖暖》感应活动“辉光的新篇”上线, 引擎焕新升级送百抽
《闪耀暖暖》感应活动“辉光的新篇”上线, 引擎焕新升级送百抽 虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料 央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声! 青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮 《天下》手游初代男团爆改出道,来幽州东摸鱼看夜景
《天下》手游初代男团爆改出道,来幽州东摸鱼看夜景 AI大模型时代:多元算力如何打破碎片化困局?
AI大模型时代:多元算力如何打破碎片化困局? AI浪潮高涨,中兴通讯迎来价值重估
AI浪潮高涨,中兴通讯迎来价值重估 阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测
阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测 团战王炸幻兽,魔域口袋版年中幻兽青鸾即将开售
团战王炸幻兽,魔域口袋版年中幻兽青鸾即将开售 利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力 福至天墉 《问道》8月万宝阁活动来袭
福至天墉 《问道》8月万宝阁活动来袭 鼎盛注册平台——开启您的财富之门,迈向成功的第一步
鼎盛注册平台——开启您的财富之门,迈向成功的第一步 155期天齐藏机四字定胆
155期天齐藏机四字定胆 《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决
《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决 《黑潮之上》明日全平台公测!中国绊爱前来应援
《黑潮之上》明日全平台公测!中国绊爱前来应援 剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略 崩坏星穹铁道3.1版本新角色是谁呢 新版本角色介绍
崩坏星穹铁道3.1版本新角色是谁呢 新版本角色介绍 鼎盛注册平台——开启您的财富之门,迈向成功的第一步
鼎盛注册平台——开启您的财富之门,迈向成功的第一步 异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启 问鼎娱乐——开启娱乐圈的新篇章
问鼎娱乐——开启娱乐圈的新篇章 23年155期南陀老道解太湖之搞辩论
23年155期南陀老道解太湖之搞辩论 在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降 虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料 《模拟城市:我是市长》华贵时代赛季精彩曝光
《模拟城市:我是市长》华贵时代赛季精彩曝光 上海地铁站打破次元壁,小红书联动头部厂商开启“游戏这个夏天”
上海地铁站打破次元壁,小红书联动头部厂商开启“游戏这个夏天” 原神阿蕾奇诺怎么配队 原神仆人配队的四种思路
原神阿蕾奇诺怎么配队 原神仆人配队的四种思路 虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料 《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线
《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线 复古至尊合击手游下载
复古至尊合击手游下载 鼎盛注册平台——开启您的财富之门,迈向成功的第一步
鼎盛注册平台——开启您的财富之门,迈向成功的第一步 OpenAI ChatGPT AI 服务再次“跳闸”
OpenAI ChatGPT AI 服务再次“跳闸” 星宸科技(301536) 探索智慧实践 洞见AI未来
星宸科技(301536) 探索智慧实践 洞见AI未来 步步为营,《第五人格》2024夏季赛第二周赛报发布
步步为营,《第五人格》2024夏季赛第二周赛报发布 上海地铁11号线遭吊车侵入 应急管理部派出工作组
上海地铁11号线遭吊车侵入 应急管理部派出工作组 金秋小长假福利来袭!CF手游排位英雄版本发布
金秋小长假福利来袭!CF手游排位英雄版本发布 利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力 2023155期桑葚福彩3d和值迷
2023155期桑葚福彩3d和值迷 《问道》双线新服今日开启 精彩福利送不停
《问道》双线新服今日开启 精彩福利送不停 亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段 《决战高尔夫》感恩有你锦标赛揭开帷幕
《决战高尔夫》感恩有你锦标赛揭开帷幕 装甲战斗之王游戏下载
装甲战斗之王游戏下载 《天下》“最有文化”的全新宋制外观演绎国韵之美
《天下》“最有文化”的全新宋制外观演绎国韵之美 律师:上诉不会加重李铁刑罚
律师:上诉不会加重李铁刑罚 决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭! 代号氐宿581手游下载
代号氐宿581手游下载 《终末阵线》x《Code Geass 叛逆的鲁路修》梦幻联动今日上线!与鲁路修一起守护机甲梦想!
《终末阵线》x《Code Geass 叛逆的鲁路修》梦幻联动今日上线!与鲁路修一起守护机甲梦想! 联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发 刚送完房产,逆水寒又花45万打造痛车
刚送完房产,逆水寒又花45万打造痛车 冰雪2020手游下载
冰雪2020手游下载 阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测
阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测 律师:上诉不会加重李铁刑罚
律师:上诉不会加重李铁刑罚 巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤 真人互动影像“游戏”,《失业了,我获得了亿万游戏财产!》值得细品
真人互动影像“游戏”,《失业了,我获得了亿万游戏财产!》值得细品 数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力
数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力 OpenAI官宣计划成立更传统营利性公司
OpenAI官宣计划成立更传统营利性公司 国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家
国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家 2025006期蓝仙子一句定三码3d图谜
2025006期蓝仙子一句定三码3d图谜 中央宣传部原副部长张建春被决定逮捕
中央宣传部原副部长张建春被决定逮捕 2021年最香游戏—《超激斗梦境》,你绝对不能错过!
2021年最香游戏—《超激斗梦境》,你绝对不能错过! OpenAI ChatGPT AI 服务再次“跳闸”
OpenAI ChatGPT AI 服务再次“跳闸” 《第五人格》二十四节气演绎录芒种篇线下活动回顾
《第五人格》二十四节气演绎录芒种篇线下活动回顾 中央宣传部原副部长张建春被决定逮捕
中央宣传部原副部长张建春被决定逮捕 绝区零紧急追捕任务应该怎么快速完成 任务完成指南
绝区零紧急追捕任务应该怎么快速完成 任务完成指南 问鼎娱乐——开启娱乐圈的新篇章
问鼎娱乐——开启娱乐圈的新篇章 蛋仔滑滑开启全新快三消经营体验,乐邀玩家进入“蛋”宇宙
蛋仔滑滑开启全新快三消经营体验,乐邀玩家进入“蛋”宇宙 一名32岁中国籍男性游客在日本滑雪场遇难
一名32岁中国籍男性游客在日本滑雪场遇难 福至天墉 《问道》8月万宝阁活动来袭
福至天墉 《问道》8月万宝阁活动来袭 中央宣传部原副部长张建春被决定逮捕
中央宣传部原副部长张建春被决定逮捕 元素大天使官方版下载
元素大天使官方版下载 鼎盛注册平台——开启您的财富之门,迈向成功的第一步
鼎盛注册平台——开启您的财富之门,迈向成功的第一步 全球上线才一周就暴雷?研究称ChatGPT搜索可能欺骗、误导用户
全球上线才一周就暴雷?研究称ChatGPT搜索可能欺骗、误导用户 和流感相似?人偏肺病毒感染逐渐增多,普遍易感
和流感相似?人偏肺病毒感染逐渐增多,普遍易感 《英魂之刃口袋版》66节狂欢庆典:英雄及皮肤大放送
《英魂之刃口袋版》66节狂欢庆典:英雄及皮肤大放送 国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家
国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家 福至天墉 《问道》8月万宝阁活动来袭
福至天墉 《问道》8月万宝阁活动来袭 多晶硅期货在广州期货交易所上市
多晶硅期货在广州期货交易所上市 《大话西游》22周年玩家情义片上线,代言人大鹏演绎兄弟情义
《大话西游》22周年玩家情义片上线,代言人大鹏演绎兄弟情义 原神5.3克洛琳德复刻抽取建议
原神5.3克洛琳德复刻抽取建议 网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利! 【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持! 摩托车逃生模拟器手机版下载
摩托车逃生模拟器手机版下载 艾塔纪元止水武器属性介绍
艾塔纪元止水武器属性介绍 “失血”的光伏,2025年等待“回血”
“失血”的光伏,2025年等待“回血” AI浪潮高涨,中兴通讯迎来价值重估
AI浪潮高涨,中兴通讯迎来价值重估 单机联网成功破壁,《燕云十六声》是如何实现“既要又要”的
单机联网成功破壁,《燕云十六声》是如何实现“既要又要”的 怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址 《坦克世界》WOC全民公开赛决赛阶段开启
《坦克世界》WOC全民公开赛决赛阶段开启 《合金弹头:觉醒》体验激爽闯关、快乐解压
《合金弹头:觉醒》体验激爽闯关、快乐解压 萤火突击公测开启,战术夺金,百万撤离
萤火突击公测开启,战术夺金,百万撤离 《模拟城市:我是市长》华贵时代赛季精彩曝光
《模拟城市:我是市长》华贵时代赛季精彩曝光 律师:上诉不会加重李铁刑罚
律师:上诉不会加重李铁刑罚 在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降 异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启 “特别的纪念日”即将到来?《光与夜之恋》惊喜预告来袭
“特别的纪念日”即将到来?《光与夜之恋》惊喜预告来袭 多人实时竞技音速手游《冠军超音速》不删档测试今日开启
多人实时竞技音速手游《冠军超音速》不删档测试今日开启 中央宣传部原副部长张建春被决定逮捕
中央宣传部原副部长张建春被决定逮捕 《天下》“最有文化”的全新宋制外观演绎国韵之美
《天下》“最有文化”的全新宋制外观演绎国韵之美 《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅 阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测
阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测 问鼎娱乐——开启娱乐圈的新篇章
问鼎娱乐——开启娱乐圈的新篇章 金秋小长假福利来袭!CF手游排位英雄版本发布
金秋小长假福利来袭!CF手游排位英雄版本发布 撤职、撤项后,黄飞若被撤稿
撤职、撤项后,黄飞若被撤稿 《模拟城市:我是市长》华贵时代赛季精彩曝光
《模拟城市:我是市长》华贵时代赛季精彩曝光 国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家
国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家 刷屏的DeepSeek
刷屏的DeepSeek 泰拉瑞亚哪个时装身后带白毛
泰拉瑞亚哪个时装身后带白毛 协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目 亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段 AI浪潮高涨,中兴通讯迎来价值重估
AI浪潮高涨,中兴通讯迎来价值重估 北方多地将度过下半年来最冷白天
北方多地将度过下半年来最冷白天 OpenAI ChatGPT AI 服务再次“跳闸”
OpenAI ChatGPT AI 服务再次“跳闸” 在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降 《保卫要塞》玩法介绍第三期,出征攻占玩法
《保卫要塞》玩法介绍第三期,出征攻占玩法 撤职、撤项后,黄飞若被撤稿
撤职、撤项后,黄飞若被撤稿 无限暖暖发卡蚱蜢获取方法在哪里
无限暖暖发卡蚱蜢获取方法在哪里 阿维塔2024年销量73606辆 同比增长140%
阿维塔2024年销量73606辆 同比增长140% 亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段 伥影重生官网在哪下载 最新官方下载安装地址
伥影重生官网在哪下载 最新官方下载安装地址 三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力 剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略 【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持! 刷屏的DeepSeek
刷屏的DeepSeek 艾塔纪元止水武器属性介绍
艾塔纪元止水武器属性介绍 AI浪潮高涨,中兴通讯迎来价值重估
AI浪潮高涨,中兴通讯迎来价值重估 媒体:有了“AI使用率”检测,会增加原创论文么
媒体:有了“AI使用率”检测,会增加原创论文么 PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中 《模拟城市:我是市长》华贵时代赛季精彩曝光
《模拟城市:我是市长》华贵时代赛季精彩曝光 AI大模型时代:多元算力如何打破碎片化困局?
AI大模型时代:多元算力如何打破碎片化困局? 《保卫要塞》玩法介绍第三期,出征攻占玩法
《保卫要塞》玩法介绍第三期,出征攻占玩法 【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持! 协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目 大话西游x幸福西饼 你不得不知道的包子
大话西游x幸福西饼 你不得不知道的包子 数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力
数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力 上海地铁11号线遭吊车侵入 应急管理部派出工作组
上海地铁11号线遭吊车侵入 应急管理部派出工作组 镰刀妹AI智能播报
镰刀妹AI智能播报 《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉 利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力 AI大模型时代:多元算力如何打破碎片化困局?
AI大模型时代:多元算力如何打破碎片化困局? 河南工会推出首位AI理论宣讲员“豫小宣”
河南工会推出首位AI理论宣讲员“豫小宣” 异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启 《天下》“最有文化”的全新宋制外观演绎国韵之美
《天下》“最有文化”的全新宋制外观演绎国韵之美 大话西游x幸福西饼 你不得不知道的包子
大话西游x幸福西饼 你不得不知道的包子 独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道 问鼎PG电子娱乐平台下载,畅享全新游戏体验
问鼎PG电子娱乐平台下载,畅享全新游戏体验 剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略 苏州大量外企撤资?官方回应:不实
苏州大量外企撤资?官方回应:不实 《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉 独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道 决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭! 星宸科技(301536) 探索智慧实践 洞见AI未来
星宸科技(301536) 探索智慧实践 洞见AI未来 数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力
数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力 《黑潮之上》明日全平台公测!中国绊爱前来应援
《黑潮之上》明日全平台公测!中国绊爱前来应援 美女丛集但有规律!《幻象回忆》独特世界观解析
美女丛集但有规律!《幻象回忆》独特世界观解析 北方多地将度过下半年来最冷白天
北方多地将度过下半年来最冷白天 原神5.3克洛琳德复刻抽取建议
原神5.3克洛琳德复刻抽取建议 一名32岁中国籍男性游客在日本滑雪场遇难
一名32岁中国籍男性游客在日本滑雪场遇难 原神阿蕾奇诺怎么配队 原神仆人配队的四种思路
原神阿蕾奇诺怎么配队 原神仆人配队的四种思路 伥影重生官网在哪下载 最新官方下载安装地址
伥影重生官网在哪下载 最新官方下载安装地址 《决战高尔夫》感恩有你锦标赛揭开帷幕
《决战高尔夫》感恩有你锦标赛揭开帷幕 美女丛集但有规律!《幻象回忆》独特世界观解析
美女丛集但有规律!《幻象回忆》独特世界观解析 泰拉瑞亚哪个时装身后带白毛
泰拉瑞亚哪个时装身后带白毛 云游敦煌,探索千年古迹,大型文创资料片即将开启!
云游敦煌,探索千年古迹,大型文创资料片即将开启! 伥影重生官网在哪下载 最新官方下载安装地址
伥影重生官网在哪下载 最新官方下载安装地址 原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议 一名32岁中国籍男性游客在日本滑雪场遇难
一名32岁中国籍男性游客在日本滑雪场遇难 【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持! 苏州大量外企撤资?官方回应:不实
苏州大量外企撤资?官方回应:不实 以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中
以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中 大话西游x幸福西饼 你不得不知道的包子
大话西游x幸福西饼 你不得不知道的包子 《模拟城市:我是市长》华贵时代赛季精彩曝光
《模拟城市:我是市长》华贵时代赛季精彩曝光 鼎盛注册平台——开启您的财富之门,迈向成功的第一步
鼎盛注册平台——开启您的财富之门,迈向成功的第一步 刚送完房产,逆水寒又花45万打造痛车
刚送完房产,逆水寒又花45万打造痛车 《决战高尔夫》感恩有你锦标赛揭开帷幕
《决战高尔夫》感恩有你锦标赛揭开帷幕 艾塔纪元止水武器属性介绍
艾塔纪元止水武器属性介绍 和流感相似?人偏肺病毒感染逐渐增多,普遍易感
和流感相似?人偏肺病毒感染逐渐增多,普遍易感 阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测
阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测 苏州大量外企撤资?官方回应:不实
苏州大量外企撤资?官方回应:不实 决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭! AI大模型时代:多元算力如何打破碎片化困局?
AI大模型时代:多元算力如何打破碎片化困局? AI浪潮高涨,中兴通讯迎来价值重估
AI浪潮高涨,中兴通讯迎来价值重估 《问道》新服挑战一触即发 海量元宝等你来拿
《问道》新服挑战一触即发 海量元宝等你来拿 以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中
以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中 阿维塔2024年销量73606辆 同比增长140%
阿维塔2024年销量73606辆 同比增长140% 独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道 利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力 AI浪潮高涨,中兴通讯迎来价值重估
AI浪潮高涨,中兴通讯迎来价值重估 异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启 散户最爱!AI巨头英伟达今年“吸金”近300亿美元
散户最爱!AI巨头英伟达今年“吸金”近300亿美元 中国联通运营公司原副总裁朱立军接受审查调查
中国联通运营公司原副总裁朱立军接受审查调查 《终末阵线》x《Code Geass 叛逆的鲁路修》梦幻联动今日上线!与鲁路修一起守护机甲梦想!
《终末阵线》x《Code Geass 叛逆的鲁路修》梦幻联动今日上线!与鲁路修一起守护机甲梦想! 《街头篮球》战术Battle SG该如何夹缝求生?
《街头篮球》战术Battle SG该如何夹缝求生? 国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家
国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家




 美高梅棋牌官网入口
美高梅棋牌官网入口 j9游会真人游戏第一品牌
j9游会真人游戏第一品牌 kaiyun云开网页版登录入口登录
kaiyun云开网页版登录入口登录 ng.28.66v1.3.5 安卓版
ng.28.66v1.3.5 安卓版 kai云体育app官网版下载
kai云体育app官网版下载 im电竞版
im电竞版 问鼎app官方下载
问鼎app官方下载 爱游戏app官方网站登录入口
爱游戏app官方网站登录入口 壹号娱乐
壹号娱乐 ng28.666南宫娱乐官网下载
ng28.666南宫娱乐官网下载 ng28.666南宫娱乐官网下载
ng28.666南宫娱乐官网下载 壹号娱乐
壹号娱乐 kaiyun官方网站登录入口
kaiyun官方网站登录入口 pg麻将胡了试玩平台
pg麻将胡了试玩平台



 策略塔防 / 259.43M / 2025-01-23
策略塔防 / 259.43M / 2025-01-23






 爱游戏app官方网站登录入口
休闲益智
爱游戏app官方网站登录入口
休闲益智
 星空体育app下载入口
休闲益智
星空体育app下载入口
休闲益智
 ng28相信品牌的力量注册入口
休闲益智
ng28相信品牌的力量注册入口
休闲益智
 365wm完美体育手机平台
休闲益智
365wm完美体育手机平台
休闲益智
 云开·全站app中心手机版
角色扮演
云开·全站app中心手机版
角色扮演
 澳门威尼克斯人网站
飞行射击
澳门威尼克斯人网站
飞行射击
 开yun体育官网入口登录app
手机游戏
开yun体育官网入口登录app
手机游戏
 星空综合体育app下载
冒险解密
星空综合体育app下载
冒险解密
 开元棋app官方下载
体育竞技
开元棋app官方下载
体育竞技
 pg免费游戏试玩模拟器
手机游戏
pg免费游戏试玩模拟器
手机游戏
 爱游戏app最新官网登录
角色扮演
爱游戏app最新官网登录
角色扮演
 kaiyun官方网站登录入口 Racing
赛车竞速
kaiyun官方网站登录入口 Racing
赛车竞速